
注册 & 登录 CNB
第一步 · 创建账号
打开 cnb.cool,选择你喜欢的方式登录。推荐使用微信扫码,一键绑定即可。
创建组织
第二步 · 准备工作
CNB 的仓库都挂在组织(Organization)下,所以需要先创建一个组织。组织名会自动校验可用性,通过后点击创建即可。
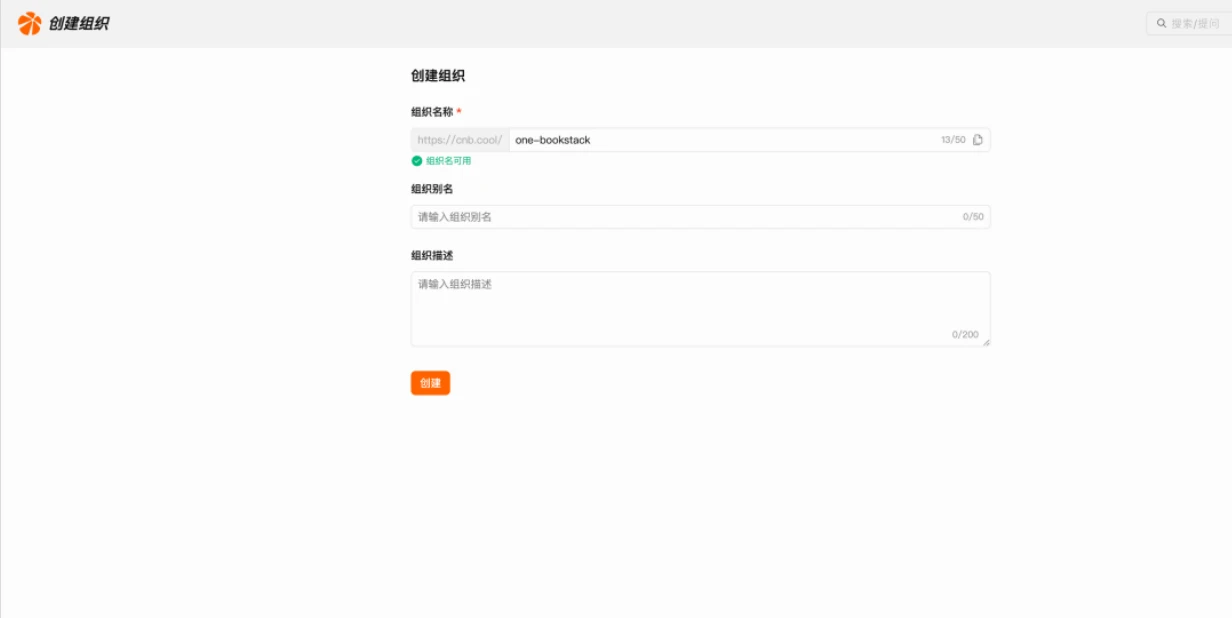
Fork 一键启动仓库
第三步 · 获取模型
进入 Ollama 一键启动仓库,例如 cnb.cool/ai-models/Ollama/OneClick/qwen3.6。 这个组织下还有很多其他模型的一键启动仓库,对哪个模型感兴趣就去对应的主页,部署流程完全一致。
依次点击:Fork → 选择刚刚创建的组织 → Fork 整个仓库 → 确认 Fork
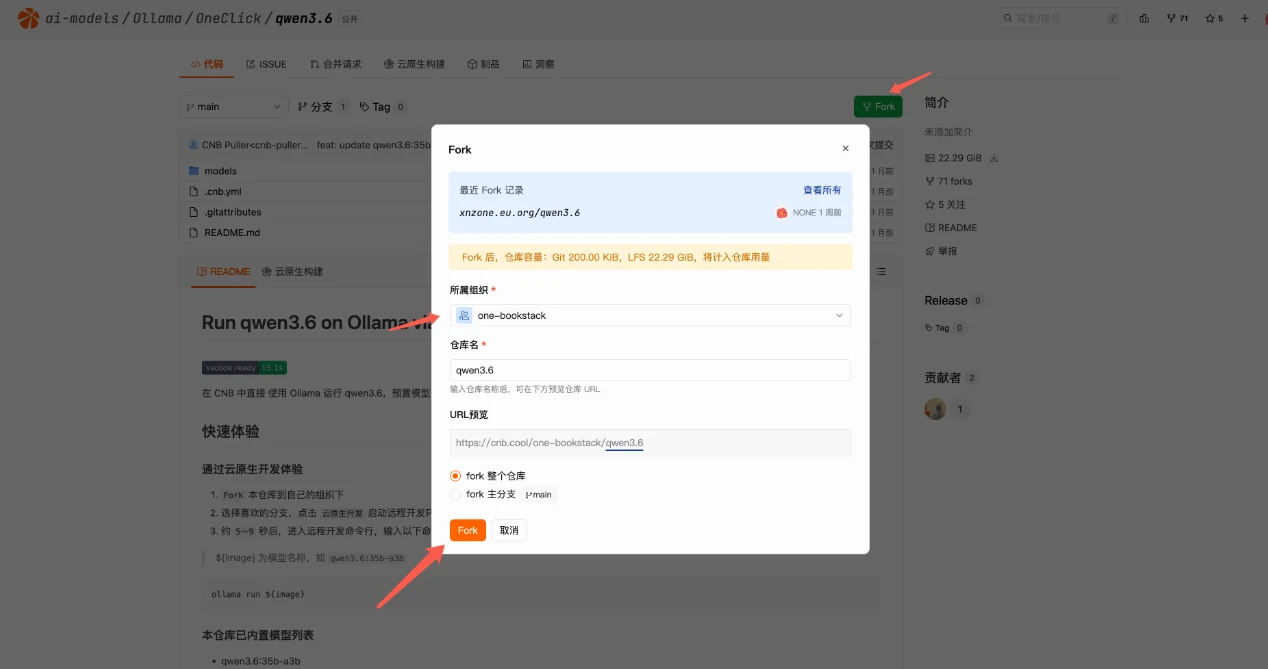
进入 Fork 后的仓库
第四步 · 确认仓库
Fork 完成后,页面会自动跳转到你选择的组织下的仓库页面,确认仓库内容已就绪。
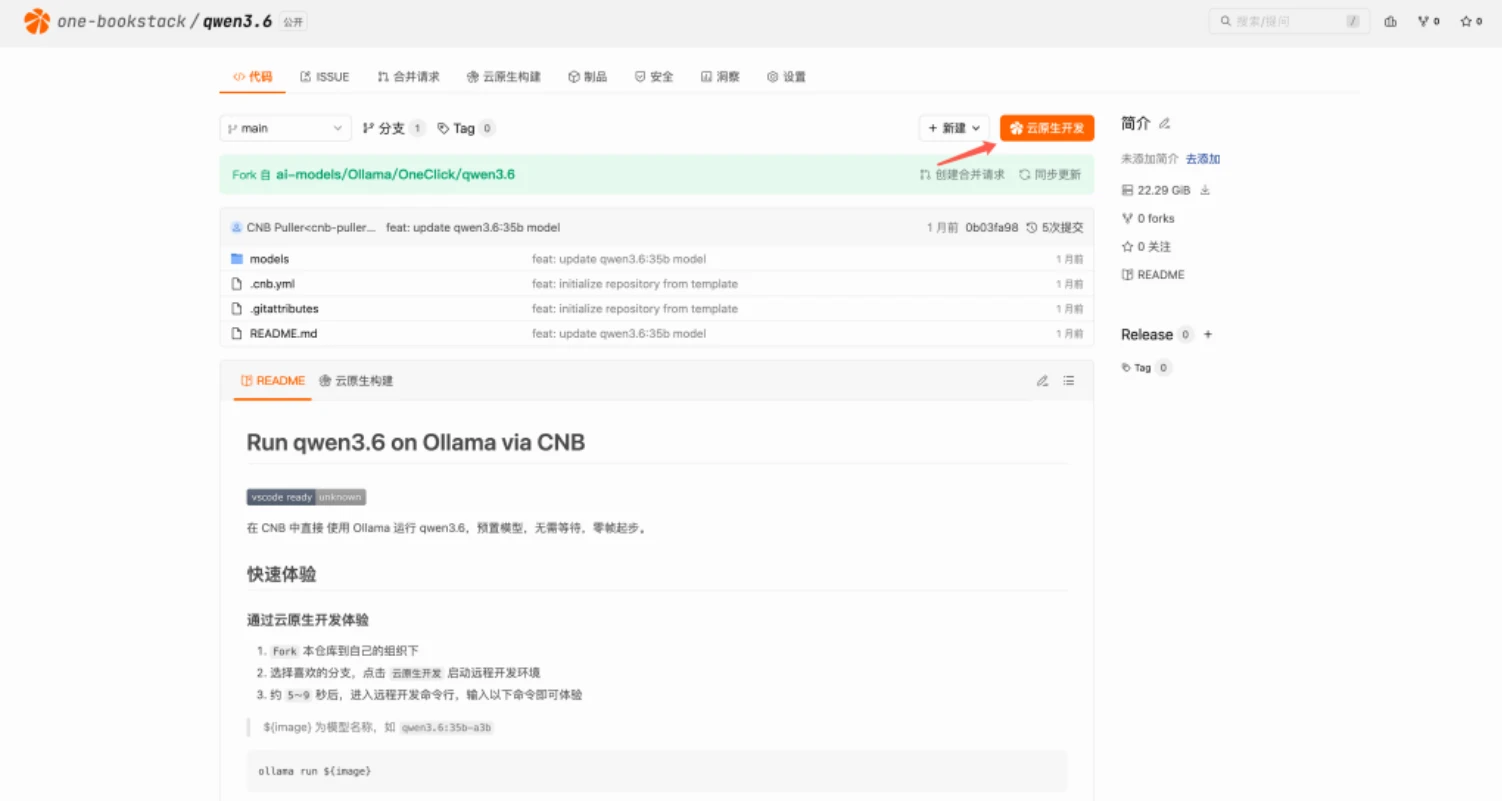
启动云原生开发环境
第五步 · 核心操作
在新页面点击右上角的「云原生开发」按钮,系统会自动创建并部署开发容器。等待几秒到几分钟,就会进入一个与 VS Code 非常相似的浏览器内开发环境。
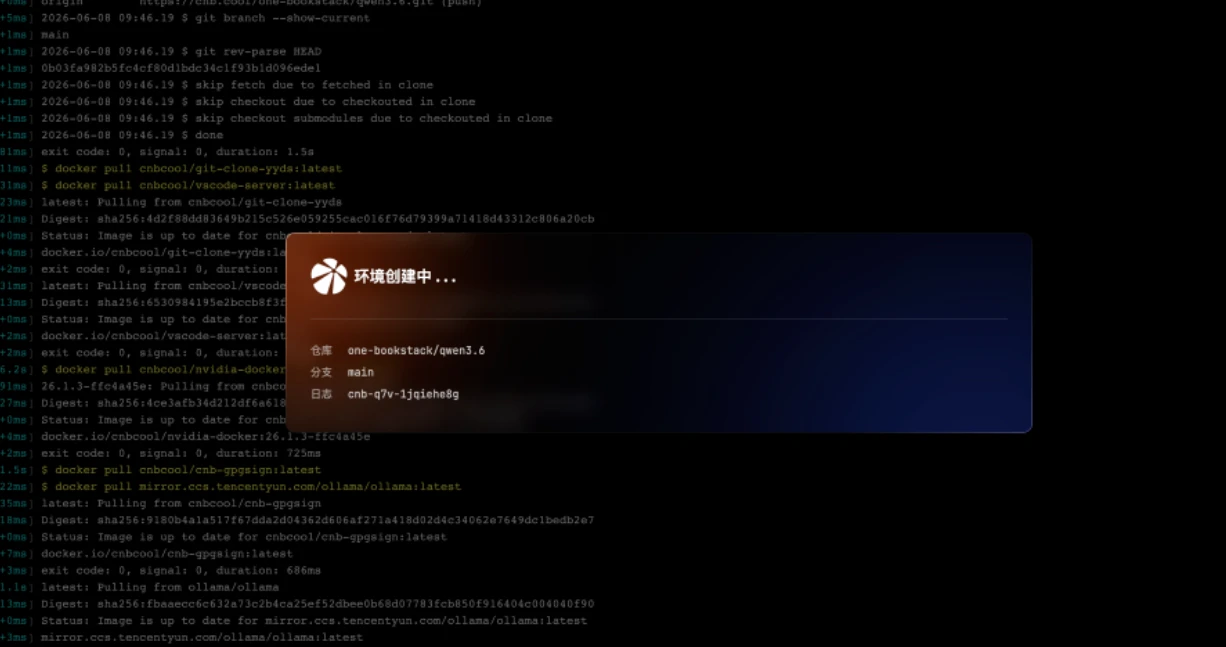
部署模型
第六步 · 一键运行
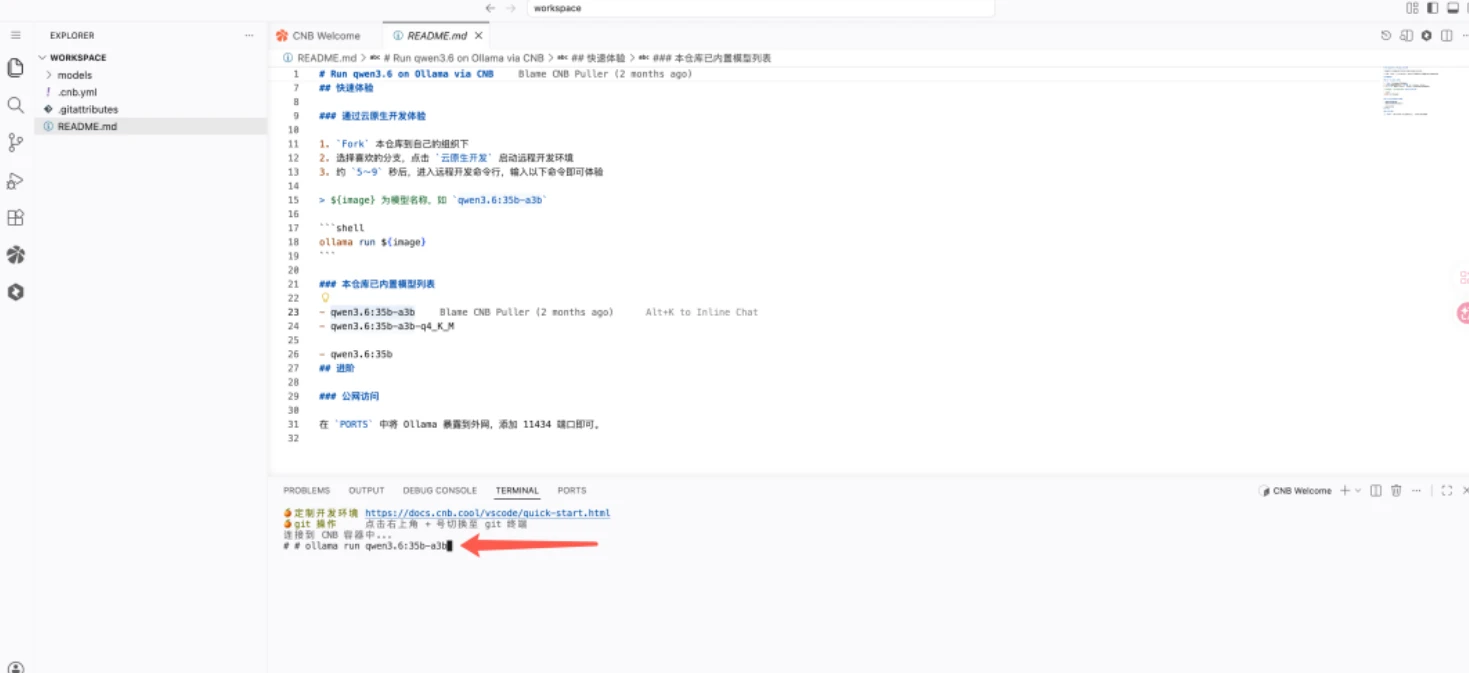
进入开发环境后,点击左侧文件树的 README.md 查看部署说明。只需一条命令,在底部 Terminal(终端) 中运行:
ollama run ${模型名称}将 ${模型名称} 替换为你要运行的模型,比如 qwen3.6、gemma-4-12b 等。
测试模型
第七步 · 验证部署
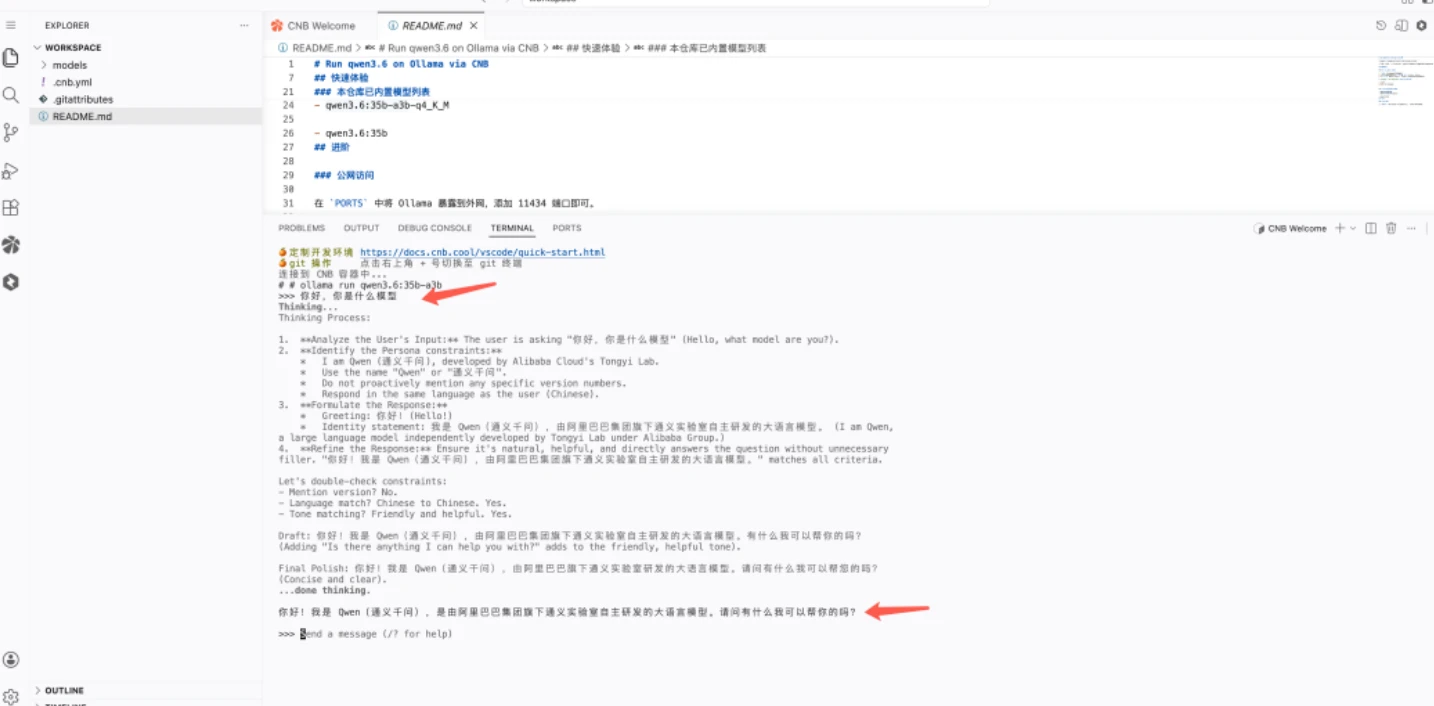
等待几分钟,终端出现 >>>> 提示符后,说明模型已经部署成功。输入一段文字进行测试即可。
示例输入:"你好,你是什么模型?"
模型会返回它的名称、版本和能力说明,代表一切正常。
开放端口,实现外部访问
第八步 · 对外开放
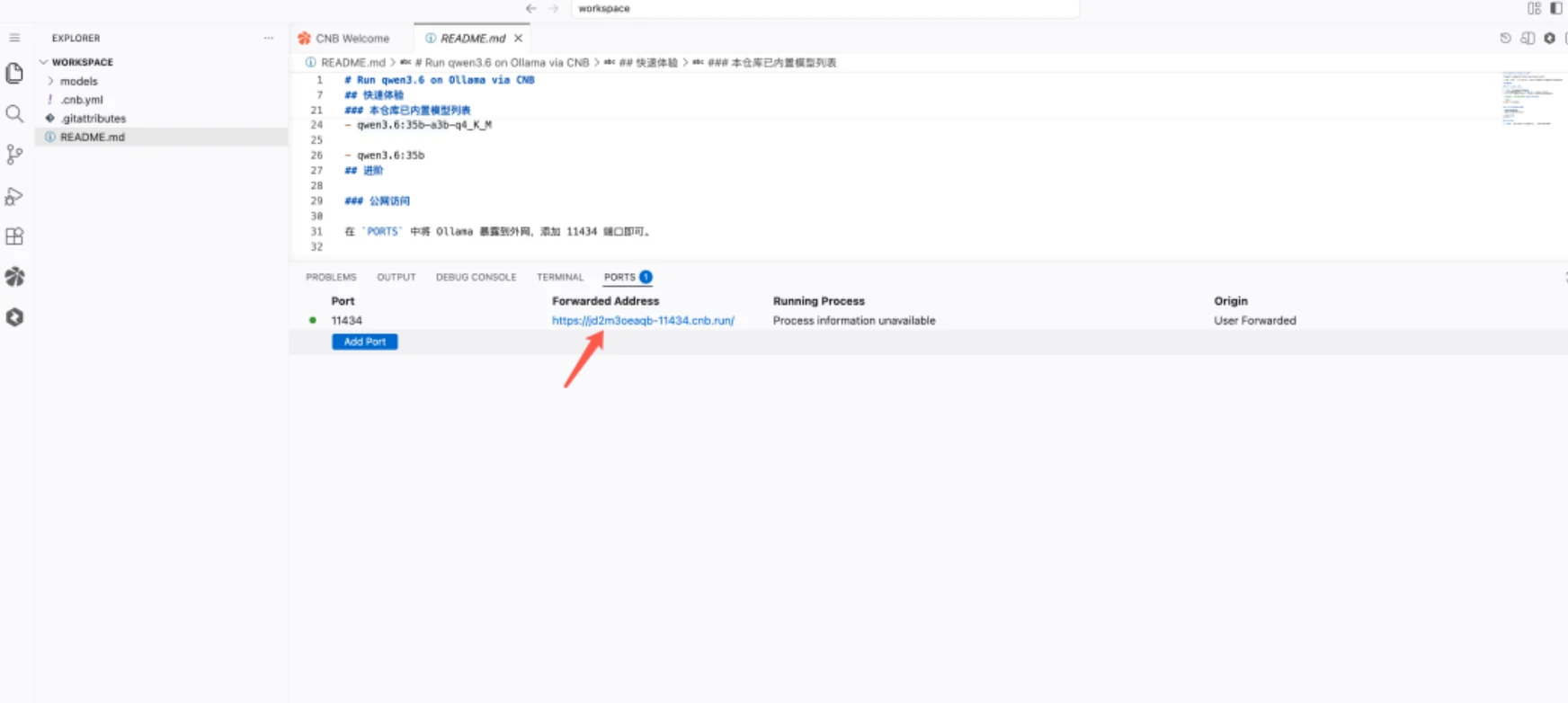
README 里也提到了端口开放的方法:在 PORT 页面输入 11434,点击 Add Port,系统会生成一个可公开访问的 URL 链接。
接入第三方平台
第九步 · 扩展使用
拿到 URL 后,你可以把这个模型接入各种支持 Ollama 协议的第三方平台。以 WorkBuddy 为例:
- 在 WorkBuddy 的 Ollama 配置中填入你的容器 URL
- API 密钥随便填即可(CNB 的 Ollama 部署默认无认证)
- 配置完成后就可以在 WorkBuddy 上直接使用这个模型了
其他支持 Ollama 协议的平台操作方式类似,按各平台的要求填入链接即可。
重要提示
使用须知
- 云原生容器48 小时后会自动销毁,请勿当作生产环境使用。
- 适合用来快速测试新模型的能力,比如最近热门的 Gemma-4-12B。
- 容器销毁后如需继续使用,重新 Fork 并启动即可,流程完全一致。